
Who’s Driving the Tariff Conversation on Bluesky?
14 de April de 2025In the fast-moving world of AI tools, ChatGPT’s Deep Research feature stands out as one of the more promising options for in-depth content retrieval. Unlike simpler tools that scrape basic data, it’s designed to investigate across multiple sources, analyze findings, and generate structured reports. But how well does it actually perform when put to the test?
We explored various AI platforms to assess their ability to extract and organize social media content — with a focus on public profiles on X (formerly Twitter). While we experimented with different tools, ChatGPT’s Deep Research ultimately became the one we used the most, mainly because it delivered the most usable results, despite some important limitations.
What We Tested
We set out to retrieve and organize all posts published by POLITICOEurope during April 2025. The goal was to compile a table showing:
- Publication date
- Full post text
- Direct link to the post
- Engagement metrics (likes, replies, reposts)
We initially tested several platforms, including DeepSeek, Qwen, and Mistral (free versions), but none produced functional outputs. We also tried Gemini Advanced and Perplexity PRO, but these platforms similarly failed to return satisfactory results for this task. In the end, ChatGPT’s Deep Research was the only tool that managed to generate usable data, though far from perfect.
The Results
Each query with Deep Research took between 15 and 30 minutes, depending on complexity and server response. The results looked promising on the surface: a structured table with dates, text, links, and engagement metrics. But on closer inspection, several problems emerged:
- Many post links were marked as unavailable or led to incorrect destinations.
- Engagement metrics were frequently missing or inaccurate.
- Some data points were entirely fabricated.
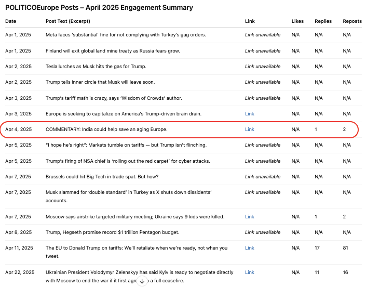
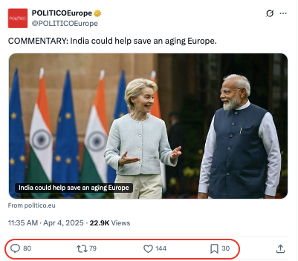
In fact, when we analyzed a sample of 10 retrieved results, we found that:
- 40% contained inaccuracies in engagement metrics.
- 60% were hallucinations — meaning they weren’t real posts from X, but instead pulled from other sources, including news articles or unrelated web content.

Additionally, many legitimate posts were simply missing from the dataset. For example, on 23 April, Deep Research retrieved only 4 posts, even though the account had actually published 46 posts that day.
Comparing Platforms
When compared to other tools, ChatGPT’s Deep Research was by far the most functional, even with its flaws. None of the alternatives we tested — including DeepSeek, Qwen, Mistral, Gemini Advanced, and Perplexity PRO — managed to retrieve usable or structured data from the X profile.
That said, Deep Research still faces several key challenges:
✅ Accuracy is inconsistent: Even the best outputs included errors or missing data, particularly in engagement metrics.
✅ Hallucinations are a real issue: A significant portion of the results were fabricated or pulled from unrelated sources.
✅ Platform access remains a barrier: Without direct API integration, data scraping is indirect and unreliable, especially from platforms like X that restrict public access.
✅ It’s not scalable: With each query taking 15–30 minutes and a cap of 25 Deep Research queries per month on the paid plan, the tool isn’t practical for large-scale or time-sensitive projects.
Final Thoughts
AI tools like Deep Research represent a meaningful step forward in automated content investigation, offering unique value for researchers, journalists, and analysts working with public data. But based on our experience, they’re not yet reliable enough for accurate, large-scale data extraction from platforms like X.
For now, traditional or programmatic solutions remain necessary for researchers who need precision and completeness at scale. Still, it’s exciting to see how fast these tools are evolving — and how close they’re getting to bridging that gap.